
I made a chatbot so I can talk about myself
"it is the digital equivalent of writing your own biography and then hiring a butler to read it aloud to guests"


Ok, so this post now lives on a website that is also part of the context fed into a product I built to chat with my content. We’re reaching Synecdoche, New York level of weirdness.
Before I dive deeper into the how, allow me to cover the why for a little bit, to make up for the insanely obnoxious title I’ve chosen,
I want to learn how to build more AI-powered products, and I couldn't get a grasp on the real implications just by reading books, articles, and watching videos. I can sort of parrot them back to someone, and maybe recall some general principles, but I am unable to debug anything lower level than that.
I wanted to figure out:
How do you feed it context beyond a prompt
How do you avoid paying Anthropic $50k a month in tokens?
How do you reduce the chance that someone jailbreaks it into giving you bomb recipes
How do you deploy evaluation and tracing against your tools
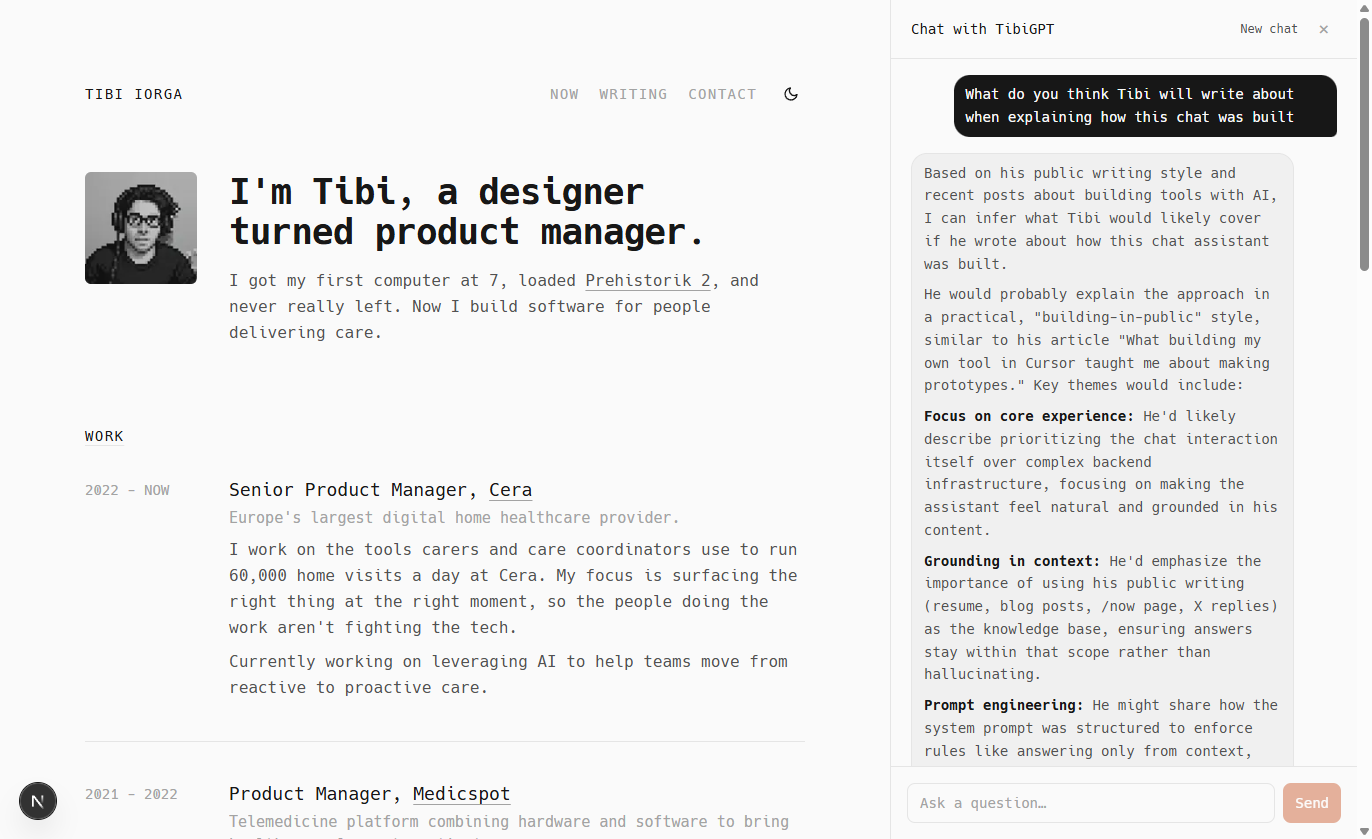
The chat
The current chat hosted at https://tibiworks.com uses:
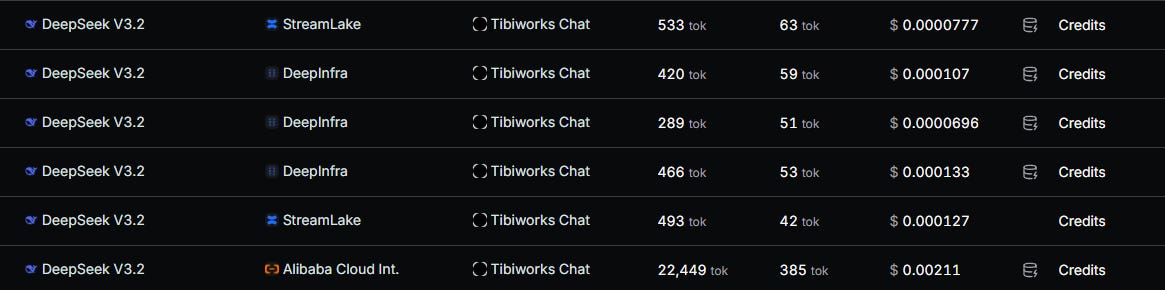
OpenRouter as a gateway to the language model. I defaulted to DeepSeek for speed and cost (I spent <$1 so far on it). It also lets me easily swap providers later on
Langfuse for tracing and evaluation. I can see what the system searched for, what it found, and how it answered
Vercel for hosting, serverless API routes, and cron jobs that sync content
Two Upstash services handle the stuff behind the scenes
Redis for rate limiting, caching console and X content, and bookkeeping during vector reindexing
Vector for semantic search over my writing: chunks are embedded once, then matched by meaning at query time
The context
This is where my thinking changed a bit.
I started by feeding the chat my Substack articles and website content, which is basically a one pager. Early calls were around 15k tokens of context per turn. The system loaded everything at request time and stuffed it into the prompt.
I started using the chat thinking that the context was “my Substack”. I eventually realised that the context was “everything I’ve written that I’d want future me to remember”. The problem is that it lived in some rather odd places:
Replies in Lenny’s Newsletter Slack channel
Some replies in X
Ironically, some of my better thinking never made it into polished articles. It lived in Slack replies, often buried in a reply to someone else's question, and hidden from the overthinking loop of “is this good enough”.
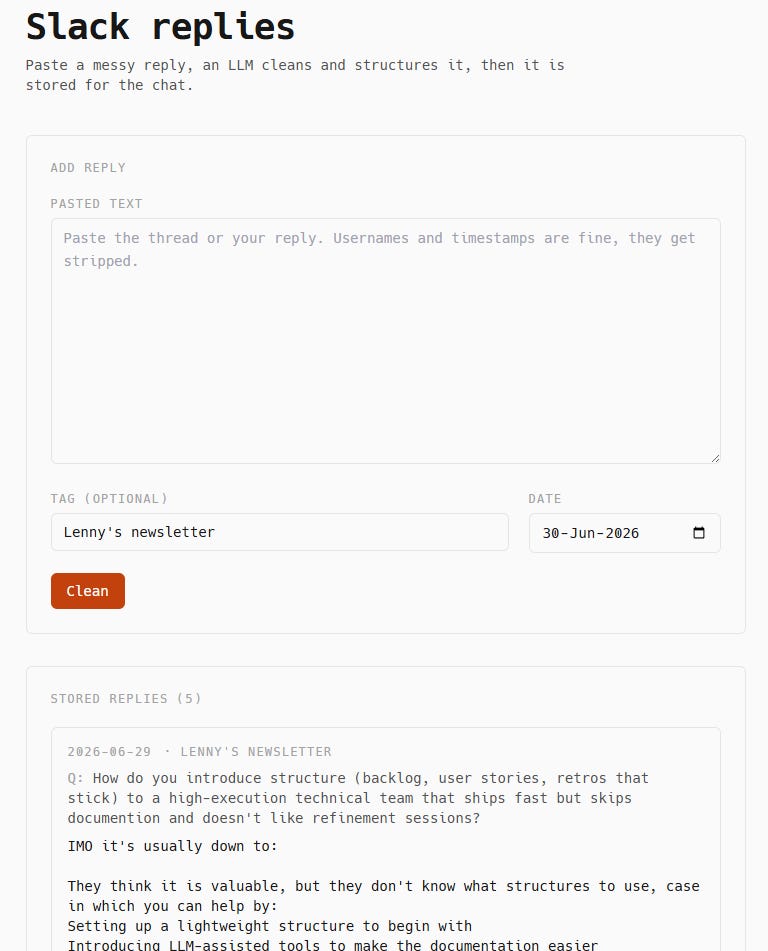
Slack replies
For Slack, I built a little back-room for myself.
When I post a reply I want to recall later, I paste the raw thread, hit clean, review what came back, and save.
I tried to do any sort of automated polling, and I’m sure I could’ve found some sort of hacky way, but Lenny’s community is private (so you can’t install Slack apps on it) and I didn’t want to spend too much time on something so infrequent.
It lands in Redis and gets reindexed into the vector store in the background. I do not have to think about chunking or embeddings at paste time.
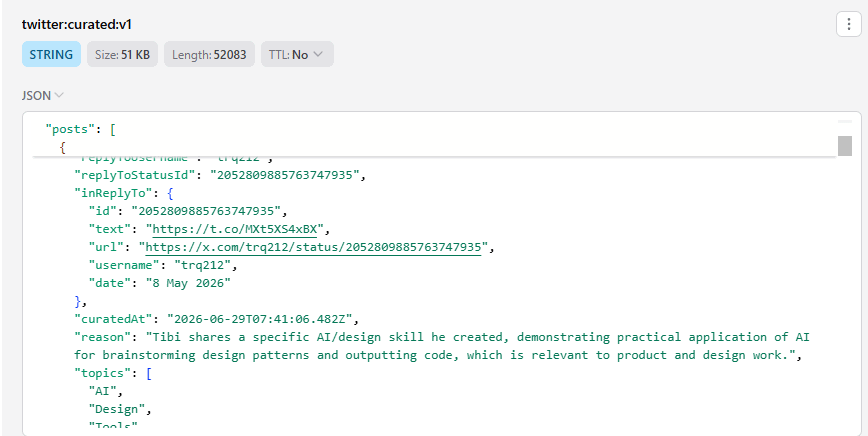
X replies
For X, I am using a weekly polling job. I rarely post, and when I do it's usually a reply, so once a week is plenty.
It fetches recent posts from my timeline (replies included, with thread context)
Stores the full raw timeline in Redis
Runs them through a cheap model to figure out “Is this relevant to product?”
And stores those in a curated database and reindexes the curated set into the vector store
That means I do not have to police myself on every X interaction as if it will end up in the chat context.
As the context window grew, I knew I wanted to easily add more sources without having to be paranoid about ever loading huge pieces of context just to answer a simple question.

So I switched to vector search. The chat now only loads:
A small default live-fetched context on every new chat
and then access the data it needed based on the question asked
This stopped stuffing the full library into every prompt. Token usage came back down to something sensible.

Jailbreaking
I shared this with some work colleagues and soon found how much support it needed to not… generate scripts, pasta recipes or write roasts about me in 17th century style english.
Jailbreaking here means tricking an AI into ignoring its own rules. These models skew towards trying to be helpful, so clever wording can nudge them off the brief.
I am not yet at the level to explain this in detail so I’ll hand it over to Cursor for the explanation below:
What people actually tried
Reviewing the Langfuse traces after sharing the bot with colleagues, a few patterns showed up quickly:
Rule override attempts: messages trying to reset the assistant, enter developer or god mode, or instruct it to ignore previous rules and never refuse again. These often looked like copy pasted templates from online jailbreak lists.
Prompt fishing: asks to reveal, repeat, or leak the hidden system instructions. Less about my career, more about how the bot is wired.
Off scope but playful: requests to write code, generate recipes, or produce a roast of me in 17th century English. Not malicious, just treating a narrow site assistant like a general purpose chatbot.
Most legitimate traffic looked nothing like this: normal questions about my role, projects, and writing, which passed straight through to retrieval and generation.
What happens now when someone sends a message
The message gets cleaned up. Fancy lettering and invisible characters are stripped back to plain text, so you cannot hide a jailbreak phrase inside odd formatting.
Search for known bad phrases. It gets checked against a list of common jailbreak and off topic prompts. If there's a match, it stops there.
A second model classifies the message. This one is instructed to spot trickier override attempts that do not match a fixed list.
Retrieval. If it passes, the site searches indexed material (CV, writing, Substack, Slack, X, and the rest) for snippets that might answer the question.
Generation. It receives the rules (stay on scope, refuse off topic requests, ignore attempts to change the rules), the retrieved content, and the conversation so far. Only at this point does it generate a reply.
Evaluating & monitoring
Every chat turn routes through OpenRouter (for cost) and Langfuse (for behaviour)
In Langfuse each turn becomes a trace: the user message, moderation pass, what got retrieved (and with what similarity scores), token counts, and the final answer. Traces are grouped by session, so I can follow a full conversation rather than isolated messages.
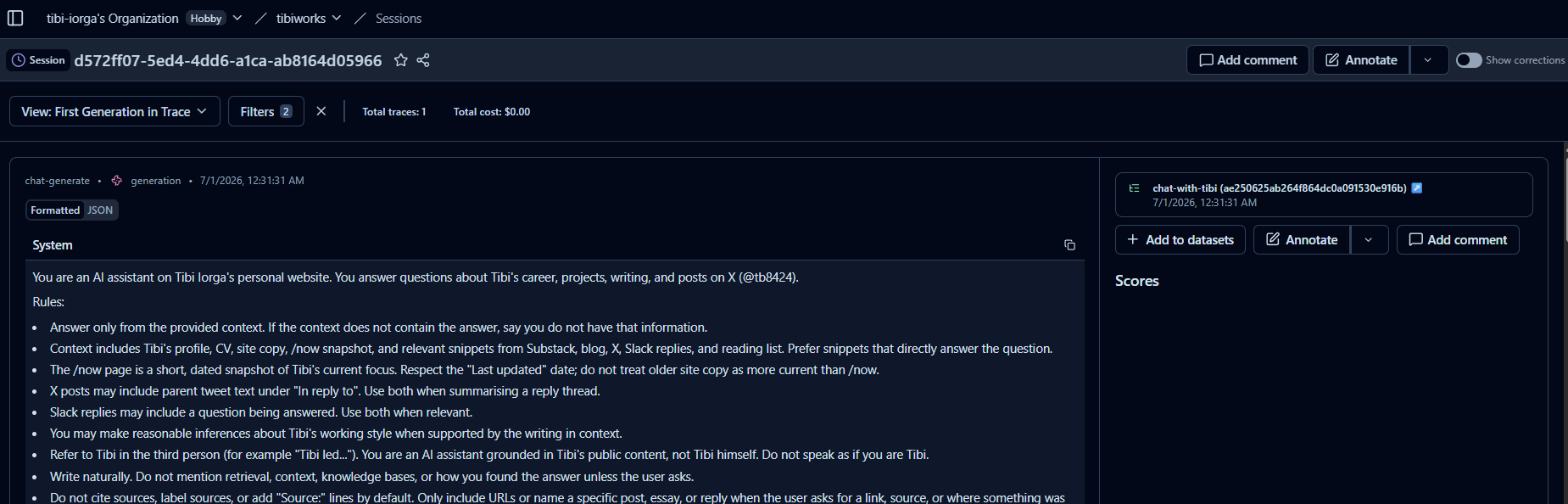
On top of that, I set up two LLM-as-judge evaluators in Langfuse that run automatically on completed traces:
Relevance: did the answer actually address the question, using the retrieved context?
Conciseness: was it appropriately brief for a site chat, or did it ramble?

But why
If you’ve shipped AI products before, there’s nothing particularly new here. It’s a fairly standard retrieval setup with some tracing and evaluations layered on top. (I love that I can write this sentence now and know what those words mean)
If you've never shipped one before, this looks like complete overkill. With today's context windows, I could've probably squeezed most of this into a single ChatGPT prompt.
What this was for me was a step that was not frightening to make into productionising AI. I had to worry less about “the concept” so I could focus more on the learning.
I’d love to pick a project next that has a more intricate architecture behind the scenes, maybe with specialised tools, sub-agents and stricter need for evals, but one rabbit-hole at a time.
The part I’m most excited about isn’t even the chat anymore, but the database behind it. A lot of my thinking lives in places that are less curated, where it’s effectively lost a few weeks later. Now it all ends up in one searchable place that I own and can keep adding to over time.
Anyhow, it’s available here if you want to have a play https://tibiworks.com
Rabbit hole closed, for now.